Author:bbdog
0x00 设备指纹
前言
最近”水哥”很是火了一把,一招微观辩水技惊四座,粘贴下其如何做到的描述如下:
王昱珩:多信息匹配,看水的时候所有信息抓住,从上往下看,亚克力杯子是没有什么细节的,工业产品很难看(辨识) 。但杯子有水之后,就有了生命,有了不一样的地方,每杯水都是独立的。
记者:魏坤琳说你是通过水的综合特征进行辨识的,除了气泡等我们常人能看到的,还结合了哪些特征?
王昱珩:气泡是依据但不是可靠依据,时间长了它会变大变小甚至掉落。看水看第一眼,给我整个的感觉,就像一个星座。中心点的时候看到一张脸,形象化。每一次闭眼都是在做一次记忆的整理。现场找那杯水,就像拿着照片找人一样,像在茫茫人海找到你爱的人一样,一眼就能看到。
在网络中,你所不知道的角落里,也有很多很多的“水哥”在注视着你们,静静的看着你们的所有活动,并默默把每一幕记了下来。并按照他自己的意愿,或好好坏的使用这些数据。
它们所使用的方法与“水哥”基本一致:每个人根据其综合特征进行辨识,都是可唯一的。通过对这些综合特征的识别,就可以把你从千万人中识别出来。
设备指纹是什么
对于某些网站来说,能够精确的识别某一用户、浏览器或者设备是一个很有诱惑性的能力,同时也是一个强需求。
它有什么用
例如,对于广告联盟或者搜索引擎来说,可以利用设备指纹知道这个用户之前搜索过什么、爱好是什么,从而在搜索结果中更好的贴合用户需求展示搜索结果;对于银行、电商等对于安全需求更高的组织来说,可以利用该技术,发现正在登陆的用户环境、设备的变化,从而阻止账号盗取、密码破解等恶意请求;当然,对于某些恶意组织,也可以利用这种技术,用于对用户进行追踪。
它的基本原理是什么
这里,姑且给出会被拍砖的结论:
服务器通过在客户端收集以下数据:
A.浏览器或设备对于特定标准的不同实现(如标准api使用情况)
B.服务器曾经下发给客户端的特定数据
C.浏览器或设备对特定事件的不同反应(如已缓存的文档)
D.浏览器用户个人特有设置
E.浏览器用户个人特有的其他信息(如浏览器历史)
通过对以上数据进行组合,并进行hash即可得到一个该设备的唯一识别码。
同时,为了保证数据的稳定性和精确度,设备指纹还需保证这些数据的不变性和稳定性(针对现在很多用户会使用隐私模式/清理cookie),于是又引出了其他的一些相关性技术,如持久化cookie等。
它是如何精确的找出你的呢?
举个例子,以下是我的数据,数据来源[https://amiunique.org/fp]:
- 我使用chrome,在某网站上的所有用户中,我是34.46 %之一
- 我使用的浏览器是chrome48.0,占比2.46%
- 我的操作系统是mac,占比13.9%
- 我的mac版本是mac 10.10,占比7.25%
- 我设置的语言是中文,占比0.56%
- 我浏览器设置的时区是UTC+8,占比1.58%
将以上的百分比进行相乘,你会发现要找到一个跟你完全一幕一样的设备,概率是很低的。 当然,如果你的设备、操作系统、浏览器等足够”平庸”,设备指纹不能保证找到你,它只能得出一个结论:现在我发现了一批人,这批人中有你。 如果你的设备、操作系统或浏览器足够特别,它就会像”水哥”一样马上把你找出来。
你到底有多特别
有人说,我用的是大众的操作系统,直接从某度下的最新版本浏览器,没有做任何额外配置,我本身还经常做清理cookie操作,我应该跟很多大众一样,为什么我会像黑暗中的萤火虫一样,如此容易被识别呢。在此简单给出理由,具体可以到相关技术中看详细实现。
-
浏览器在使用过程中,所使用的缓存机制会暴露。
你最近访问过支付宝,那么在缓存期间,访问支付宝的响应速度会很快。这些对于不同网站的访问速度,可以得出类似用户访问历史的数据,而每个人这份数据都是不同的,你爱淘宝我爱天猫就是如此。 -
浏览器的实现机制、设备的性能会暴露。
用i7内核的电脑和酷睿2的电脑对同一段计算任务的计算时间,会暴露你的硬件差异。 -
你所安装的插件和字体会暴露你。
-
你清除了cookie,然而根本没有清理干净。
-
历史上的数据会暴露你。
......
如果一个部署了设备指纹的网站,可以完美的拿到上述的这些数据,那么它基本上可以百分百的断定你是谁,然后捞出你在某天某月看小电影的记录。
它具体包含哪些技术
首先,基于相关技术的时间点和其对抗的难度,整理如下图所示。
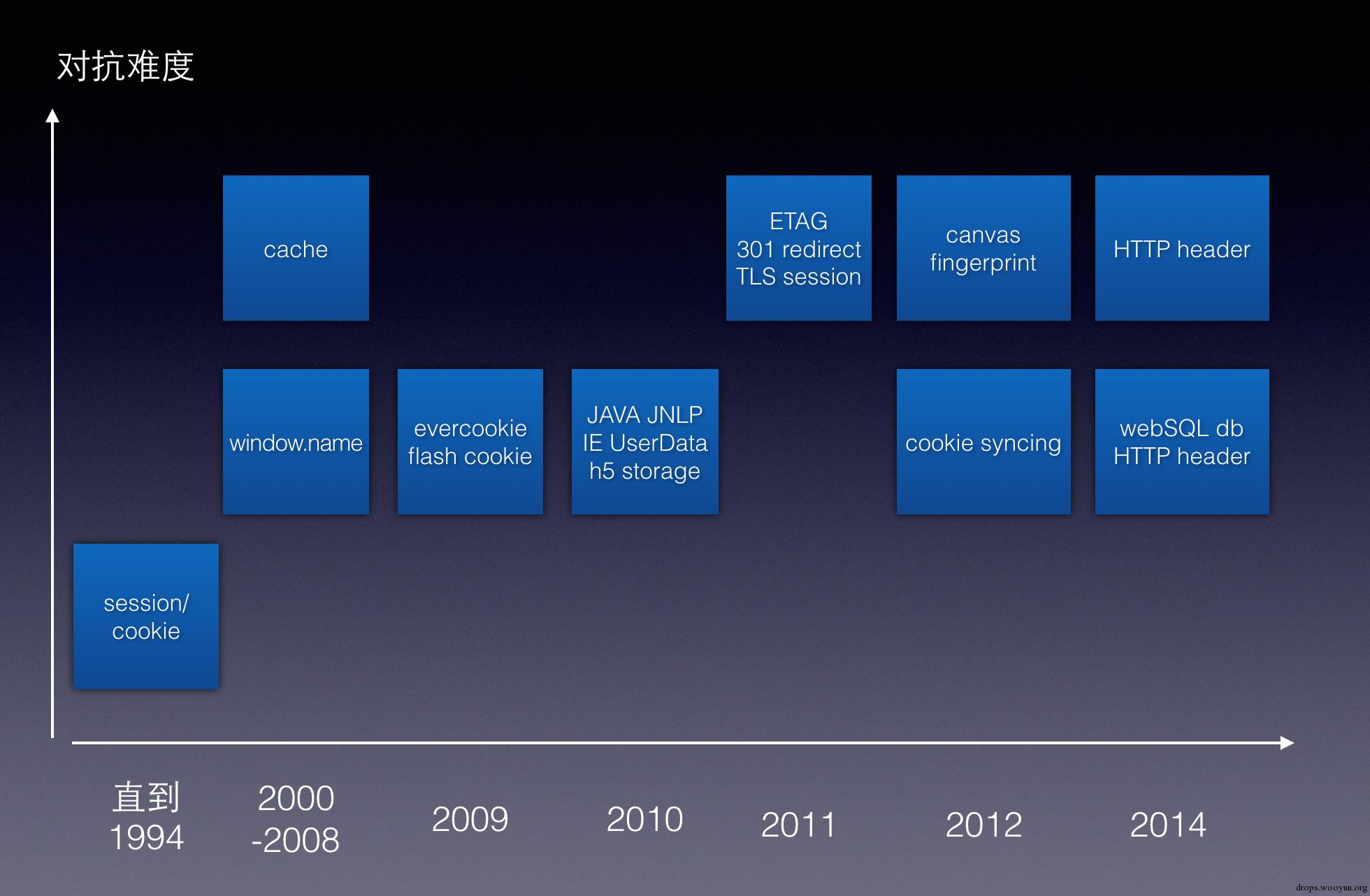
session/cookie
这是实现方式最简单,也是应用最普遍的方式。 通过浏览器set-cookie存储数据(UUID)到客户端,然后在其他请求时候附在头部里即可完成。 缺点是,通过手动清理、禁止写入等可以很简单的阻拦,导致数据稳定性降低。
window.name等dom操作
window.name可以存储最多2MB的数据,可以用于一些特殊的场合进行数据传递,不过这种方法比较trick,没有太多人使用。
基于缓存的识别
基于缓存的识别大致上可以分为几类:
-
每人一份特有的缓存文件
比如服务器返回给每个用户的html中,隐含一个特殊的div,id直接用UUID生成。用户下载一次以后,因为缓存的缘故,这个id就会和其浏览器、设备绑定。 -
加载速度区分
有缓存数据肯定比没缓存的数据下载速度快。
具体做法通常是:访问一个很少不会有人访问的地址,得到一个下载的基准值,然后再访问一次,得到缓存的一个基准值。然后访问一个准备好的常见网站的列表,看处于缓存状态的有哪些网站。 -
ETAG/LastModify
通过滥用这两个header,比如设置ETAG超时时间超长,并且把UUID写在ETAG中(ETAG支持最高81864比特),那这个用户就可以在超时前被一直锁定跟踪 -
DNS缓存
该技术与加载速度区分并无本质区别,只是dns缓存是利用dns查询时间查询的长短等进行的,在此不做赘述。 
如果可以完美的得到每个用户最近访问的网站,那基本可以完成精准定位了。
这里先贴一个2010的css历史记录嗅探的问题:

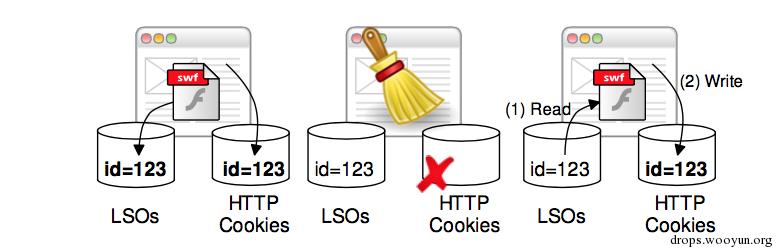
持久化cookie/Flash cookie/evercookie/h5 stroage/webDB
该技术其实是对cookie技术的一个补充。因为,越来越多的普通用户会清理cookie,因此导致无法对用户进行识别,因为每次看到用户都是全新的用户。
所谓的持久化cookie,无非就是将数据尽可能的藏在了更多的猥琐的地方。比如flash中(flash可做到多个浏览器、多域下的数据共享,因此被广泛使用),h5的各种生命周期的storage中,webDB中、IE的userdata中等。
如果用户不能事无巨细的清理干净。一旦有一个地方未清理完,就会把清理的部分完全覆盖回来。
简单流程图如下:
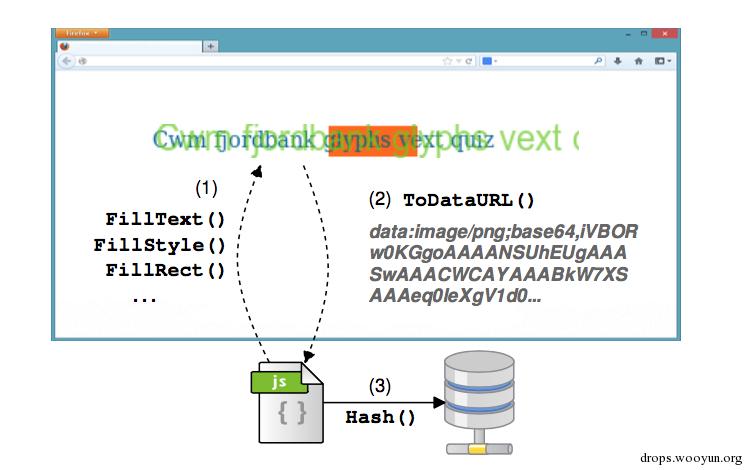
帆布指纹
这是较新的一种技术,是利用不同浏览器不同的设别实现会在canvas绘图这以功能中,同样的内容,会绘制出具有细小细节差别的图片。 通过对这些图片数据进行hash,可以得到一个粗略的指纹。该指纹能够识别出了某种GPU在安装了某种字体下的群体。但是单一使用该数据进行判断误判较高,一般还会结合其他技术综合判断。 如下,即是对同样的一段带表情带背景文字在不同设备上渲染出的图像显示。

利用不同设备上的默认字体和显示的不同,笑脸表情在各个系统上作图如下:

具体生成方法如下:
- 创建cavas环境,该canvas可以是不可见的,因此对用户完全无感知。
- 设置要作图的类型,字体等,调用api:fillRect、fillText、fillStyle等
- 对已经完成的图,调用api:canvas.toDataURL(),即可得到图的base64表示,采用一种hash算法,即可完成hash计算
- 将这个hash即可作为该设备设备指纹的一个组成部分。
Flash/Java/JAVASCRIPT等 基本数据采集
设备指纹也需要采集尽量多的数据进行区分,数据采集方式可以通过Flash、java applet(现在基本没有了)、js。
采集包括:
- 操作系统类型、操作系统版本
- 浏览器useagent、浏览器的平台
- webgl Vendor 、webgl render
- 是否支持image、是否支持js
- 内容编码、设置的时区、设置文本语言、设置接受压缩格式
- 屏幕分辨率、color depth
- 浏览器安装的插件、安装的字体
- http请求发起时的头部
- webRTC 等等
0x01 end
最后,还是表达下我对“水哥”的憧憬,附上我喜欢的一个图:

0x02 refer
-
Mowery, Keaton, et al. "Fingerprinting information in JavaScript implementations." Proceedings of W2SP 2 (2011).
-
Bujlow, Tomasz, et al. "Web Tracking: Mechanisms, Implications, and Defenses." arXiv preprint arXiv:1507.07872 (2015).
-
[https://zyan.scripts.mit.edu/presentations/toorcon2015.pdf]
-
Acar, Gunes, et al. "The web never forgets: Persistent tracking mechanisms in the wild." Proceedings of the 2014 ACM SIGSAC Conference on Computer and Communications Security. ACM, 2014.
-
Mowery, Keaton, et al. "Fingerprinting information in JavaScript implementations." Proceedings of W2SP 2 (2011).
-
Laperdrix, Pierre, Walter Rudametkin, and Benoit Baudry. "Beauty and the Beast: Diverting modern web browsers to build unique browser fingerprints."37th IEEE Symposium on Security and Privacy (S&P 2016). 2016.
-
Acar, Gunes, et al. "The web never forgets: Persistent tracking mechanisms in the wild." Proceedings of the 2014 ACM SIGSAC Conference on Computer and Communications Security. ACM, 2014.
-
Fifield, David, and Serge Egelman. "Fingerprinting web users through font metrics." Financial Cryptography and Data Security. Springer Berlin Heidelberg, 2015. 107-124.
-
Sánchez-Rola, Iskander, et al. "Tracking Users Like There is No Tomorrow: Privacy on the Current Internet." International Joint Conference. Springer International Publishing, 2015.
-
Mowery, Keaton, and Hovav Shacham. "Pixel perfect: Fingerprinting canvas in HTML5." Proceedings of W2SP (2012).