先插播一个信息,在两天前的 G.O.S.S.I.P 阅读推荐 2024-03-11 A Friend's Eye is A Good Mirror 中介绍的Perry系统,其开源代码(https://github.com/VoodooChild99/perry )主要内容目前还在dev分支中,大家如果要查看细节,记得切换到该分支。
小时候读《三国演义》一直耿耿于怀的一件事,是刘备坐拥五虎将却没能一统天下;今天读完我们要介绍的这篇论文,你会发现即使坐拥五大(静态)代码缺陷检测工具(static bug detector),却现实中1%的bug都检测不出来。究竟原因是为什么呢?请看ISSRE 2023研究论文Automatic Static Bug Detection for Machine Learning Libraries: Are We There Yet?

首先要强调的是,这不是第一篇研究代码缺陷检测工具的有效性的论文,不过本文作者主要关注的是在当前最热门的机器学习(ML)相关的代码库中找bug的需求。作者对4个非常热门的ML代码库——Mlpack、MXNet、PyTorch和TensorFlow的代码提交记录进行了分析,从中筛选出410条和bug及修复相关的commit记录,然后想用代码缺陷检测工具来扫描一把,看看到底这些已经被人工发现的bug,有几个能被代码缺陷检测工具的自动化扫描给捕获到。究竟结果如何,请继续往下看。
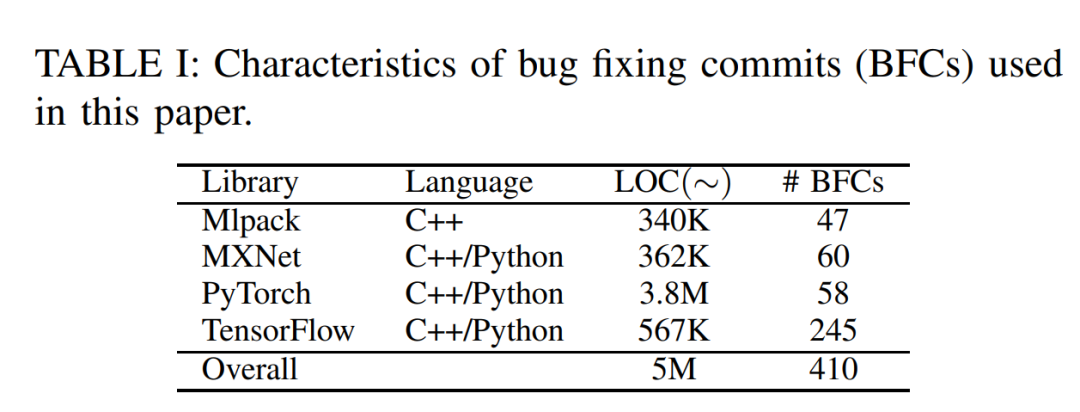
下面有请本文涉及到的“五虎将”出场:
FlawFinder
https://dwheeler.com/flawfinder/
RATS
https://github.com/andrew-d/rough-auditing-tool-for-security

Cppcheck
https://cppcheck.sourceforge.io/
Infer
https://fbinfer.com/
Clang Static Analyzer
https://clang-analyzer.llvm.org/
选手都已经到场,作者也帮我们总结了一下这几个工具的分析能力特性:

接下来,就要揭晓代码分析的结果了,你可以先不看下面的表格,猜测一下代码缺陷检测工具的表现,也可以看一下表格,然后再猜测一下这些结果的准确率?
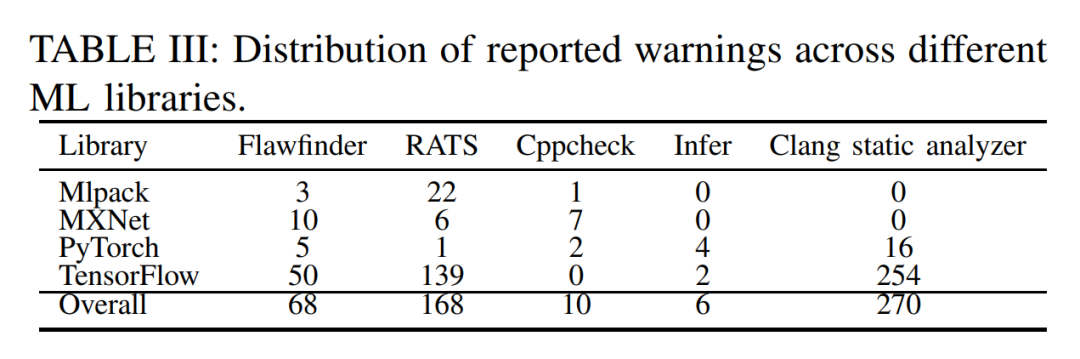
猜完了吗?来看看结果:针对被测试对象包含的总共410个bug,五大工具联手也只发现了其中的4个;更具体一点,在bug检测的True Positive Rate(TPR)统计中,三个工具直接挂零,剩余两个也是惨不忍睹——低于5%;而且杀人诛心的是,在bug检测的False Negative Rate(FNR)统计中,所有的工具都展现出了很高误报率。也就是说,虽然找不到真正的bug,但是在报告假的bug时候你们却很在行啊!

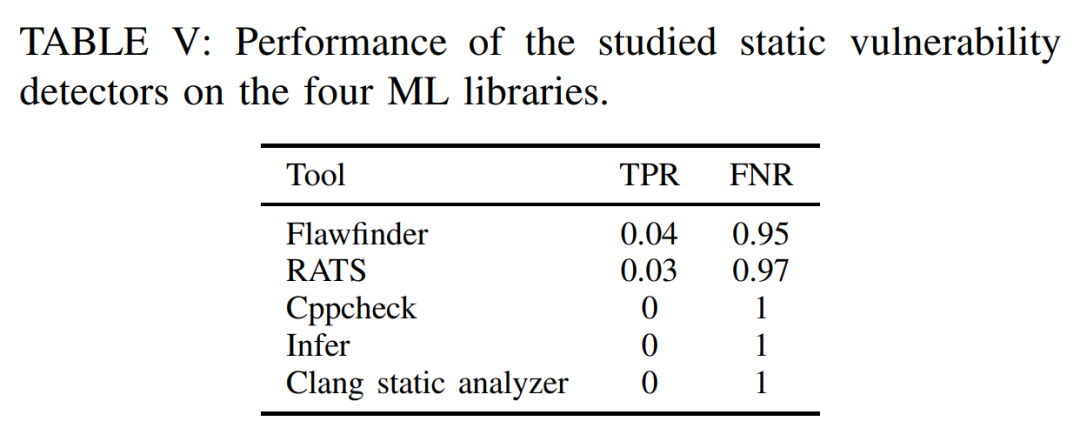
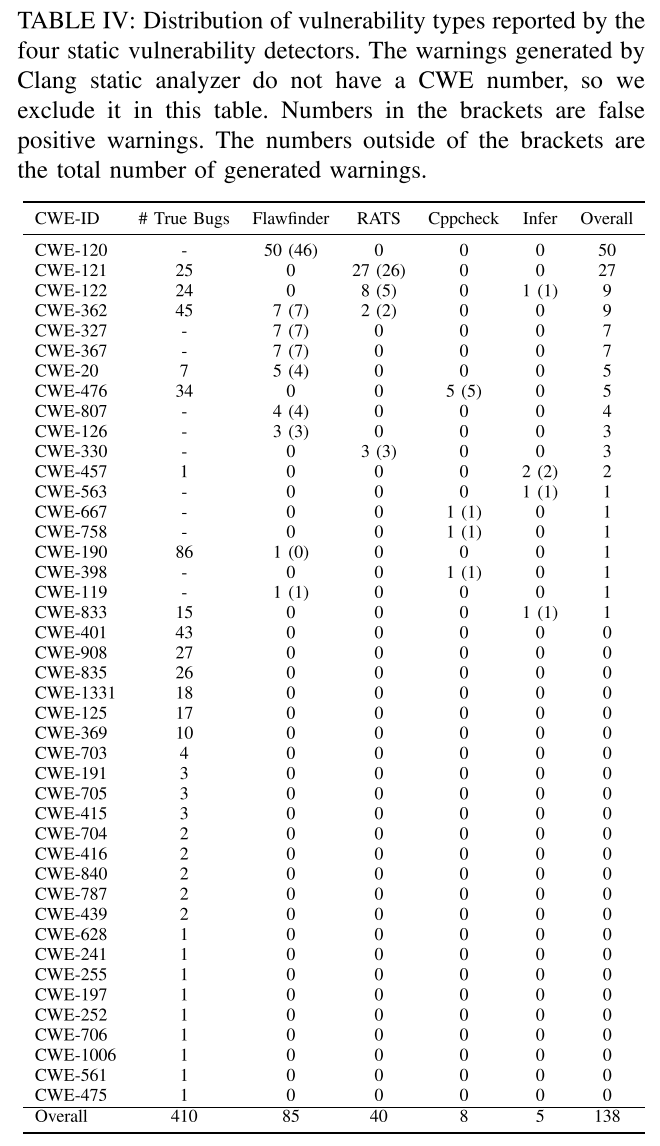
当然,如果只给结论(噱头)不解释原因,那就成了营销号而不是科学研究了。所以我们的重点是揭示到底这些知名的代码缺陷检测工具本身的缺陷是什么,怎么就表现得如此糟糕呢?从论文的Section IV.C开始,作者来深入剖析了工具表现糟糕的根本原因:
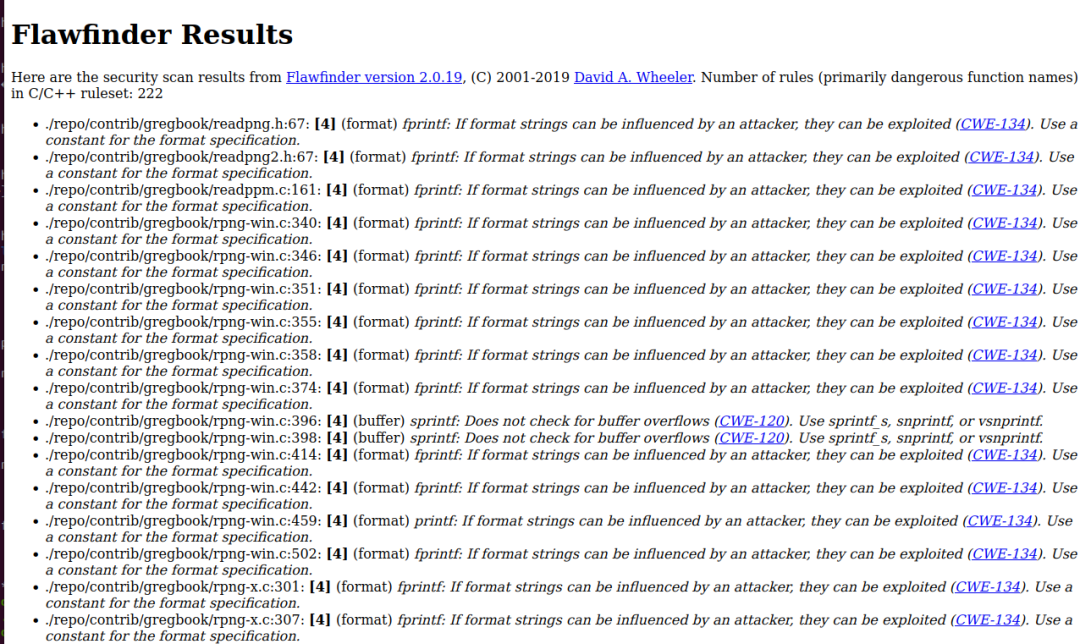
对于Flawfinder和RATS(这两个工具的技术路线比较类似),出于不知道什么考虑(也许是要保证没有漏报),它们把代码出现的C/C++ API调用(这两个工具预先定义了超过200个高风险C/C++ API列表)一概标记为“potentially buggy”,显然是宁可错杀一千,不可放过一个;同时,它们缺少对ML代码库的高级语义的理解能力(也就是缺少我们G.O.S.S.I.P荣誉出品的
Goshawk工具的那种理解自定义API的能力),像代码中涉及到的CleanMemory和delete_mat这种自定义内存释放函数就完全无法理解,更不要说检测漏洞(Goshawk工具笑而不语)。当然,Flawfinder和RATS的主要问题是缺少高级的数据流和控制流分析能力,因此只能用来检测一些非常简单的bug,例如下图中这个例子,如果有基本的数据依赖分析能力,代码缺陷检测工具可能就能报告出来第88行和第90行潜在的越界访问bug(因为input_shape和input_h_shape的值不一定是有效的,Dim函数也就不一定能获取到rank更高的情况下的值)。

Cppcheck在分析ML代码库的时候,遇到的主要挑战是没法很好地理解一些涉及到数组(或者容器类数据结构)成员的管理问题,所以检测不到相关的内存越界访问,不过这个好像也是很多静态代码缺陷检测工具的通病了;而且Cppcheck的控制流分析相对比较简单,对涉及到复杂代码结构的分析,Cppcheck倾向于放弃,因此会有一些漏报。不过这里我们再给
Goshawk工具打打广告,因为作者举出来的例子(CVE-2022-23585)又是一个因为无法理解自定义内存管理函数(png::CommonFreeDecode(&decode))而导致漏报的问题~Infer的问题是即使它已经使用了强大的符号执行引擎和数据流/控制流分析,在处理一些越界问题上依然不太足够,例如下面这个例子中,程序员忘记检查
shape2的维数是否大于shape1的维数,而只是假定shape2的维数一定是更大的,而直接返回了shape1.Dims(index1)(实际上应该先确定到底shape1和shape2谁的维数更小,然后返回维数小的那个对象的相关值)。不过这个看起来好像对静态代码缺陷检测工具的要求有点高~~~
Clang Static Analyzer在实战中表现不佳有两个原因:第一个原因是它内置的检测规则(虽然有25大类)没有针对ML代码库的(虽然你可以自己开发一些新的checker,但这个已经超出了本文的研究范围);第二个原因是它的flow analysis有点过于敏感——经常会给出误报,实际上对于C++代码来说,Clang Static Analyzer支持得并不好,搞一些复杂的分析反而容易出错。
作者基于上面这些分析,给出了一堆建议,不过这些建议都是站在观察者的角度。而我们根据自己常年对代码缺陷检测工具开发的经验,给出了我们自己的建议:
对于新型的代码场景如(机器学习、数据分析),新型的代码架构、模型以及问题模式都和原有的CPU为运算模型的场景不一致,应使用创新的方法去检测。
更多地使用函数摘要,降低分析复杂度
代码检测工具的输出结果一般是给研发人员解读,结果中一定要有足够丰富的信息,提高可解释能力、可读性,否则很难得到开发者的认可。
基于使用效果持续优化很重要,没有哪个工具一开始是万能的,不断进化的工具才是最好的。
如果你想关注更多关于代码缺陷检测的相关研究和相关工具,也欢迎关注G.O.S.S.I.P孵化企业——蜚语科技。蜚语科技研发的代码分析系统Corax和现有的主流静态代码缺陷检测工具相比,通过不断测试真实世界的代码缺陷来提升检测能力,在学习中进步成长~ 如果想要了解Corax的更多信息,也欢迎大家关注蜚语科技,索取可用的测试版本!
论文:https://arxiv.org/pdf/2307.04080.pdf
Artifacts:https://anonymous.4open.science/r/ISSRE2023SATS-E255/README.md